OpenAI Crawlers/Bots IP Address

OpenAI has web crawlers that is used to interact with the online content like website/blog, etc to get more context. They can be either user request (for enable when we use web search feature in ChatGPT, it fetchs the real time context from the internet)
They’ve 3 types of web crawlers/bot and each one performs specific tasks.
| Bot User Agent | What It’s Used For (TL;DR) | IP Address | Full User-Agent String |
|---|---|---|---|
| OAI-SearchBot | Used to link to and surface websites in ChatGPT search results (not for training). | https://openai.com/searchbot.json | OAI-SearchBot/1.0; +https://openai.com/searchbot |
| ChatGPT-User | For user actions in ChatGPT and Custom GPTs. Not used for automatic crawling or training. | https://openai.com/chatgpt-user.json | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot |
| GPTBot | Crawls content to train generative AI models. Sites can disallow it to opt out of training. | https://openai.com/gptbot.json | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.1; +https://openai.com/gptbot |
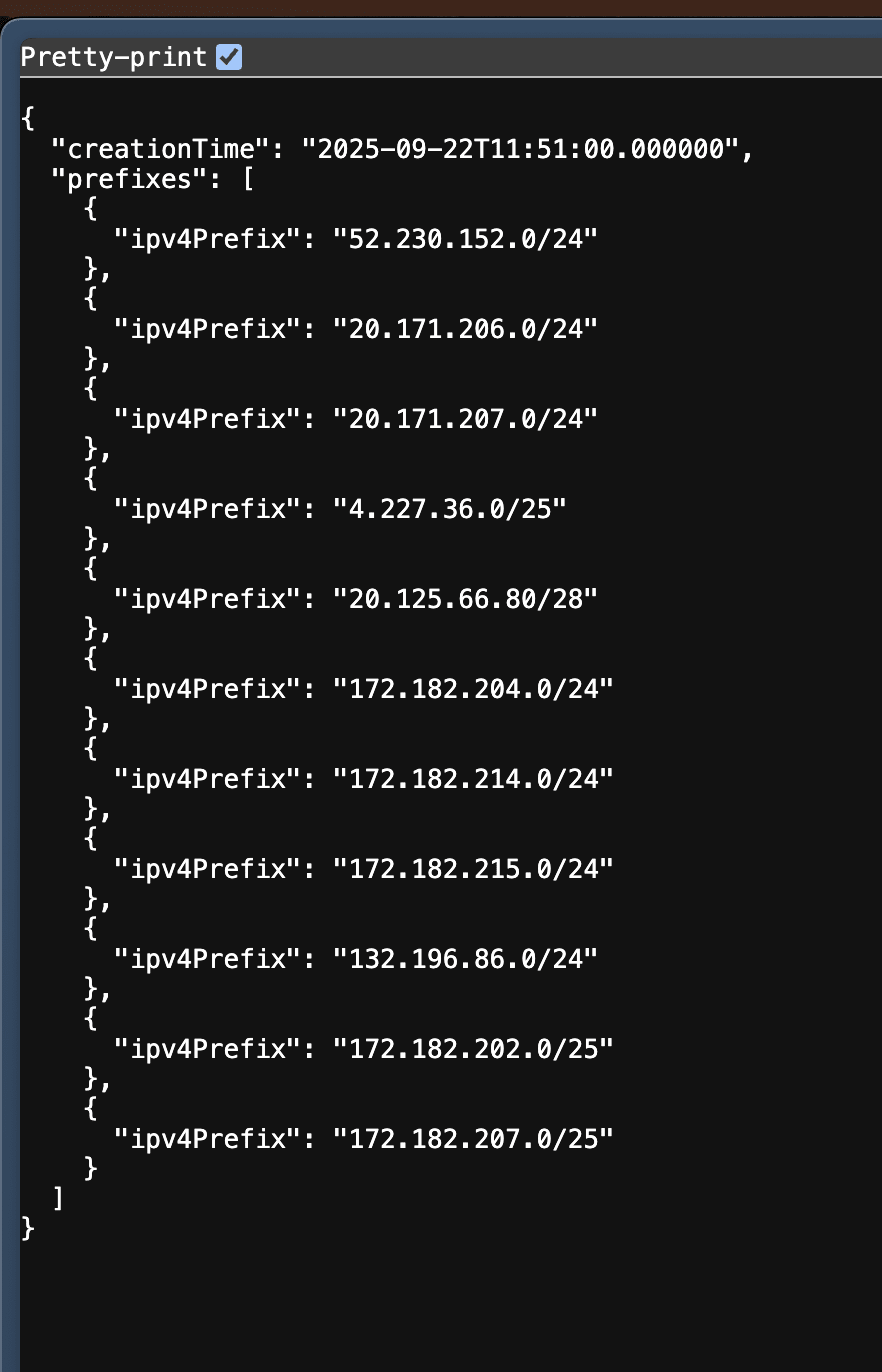
You can use those IP address to validate those bots (and perform some action like allowing/dening)