How to use Google Gemma 4 models on Amazon Bedrock

Gemma 4 models are now available on AWS Bedrock where you can just pay based on usage.
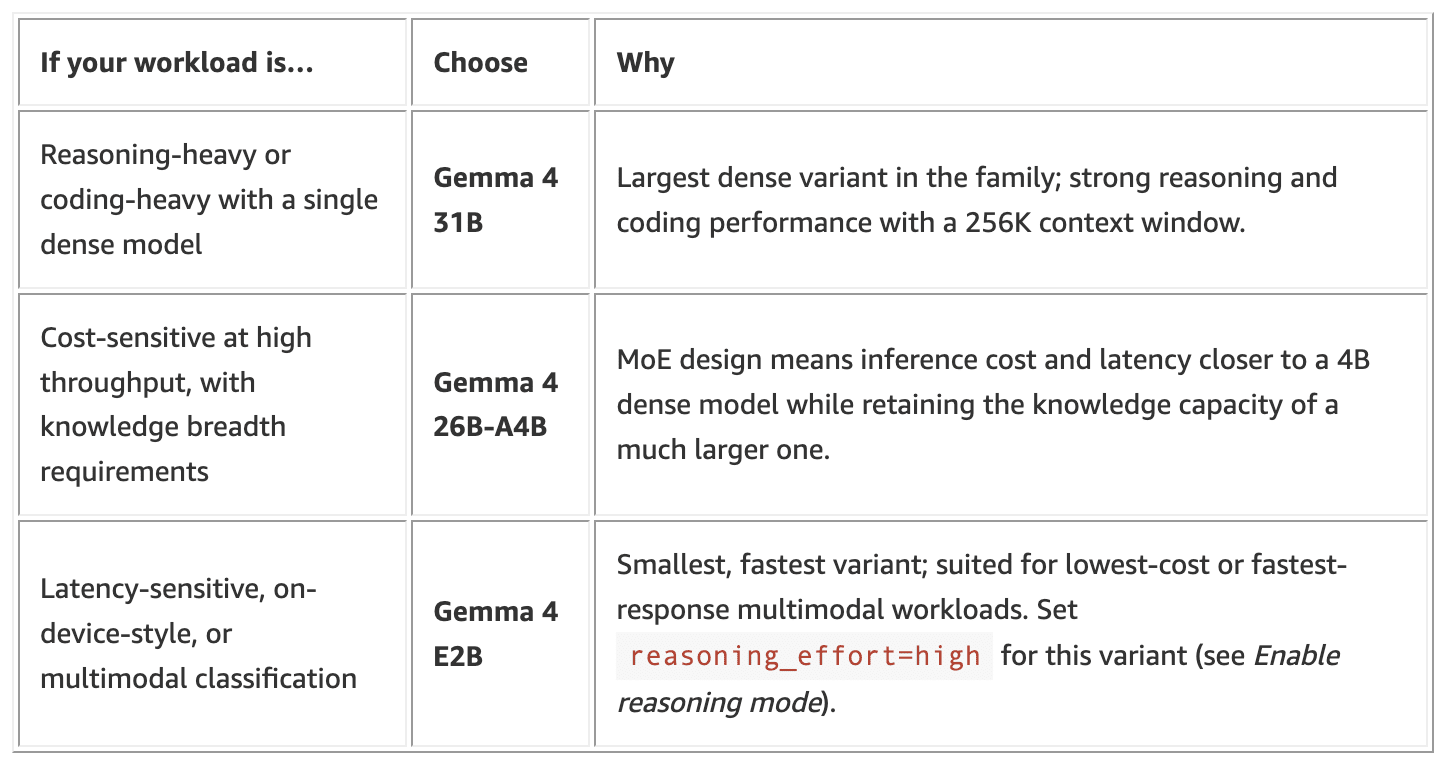
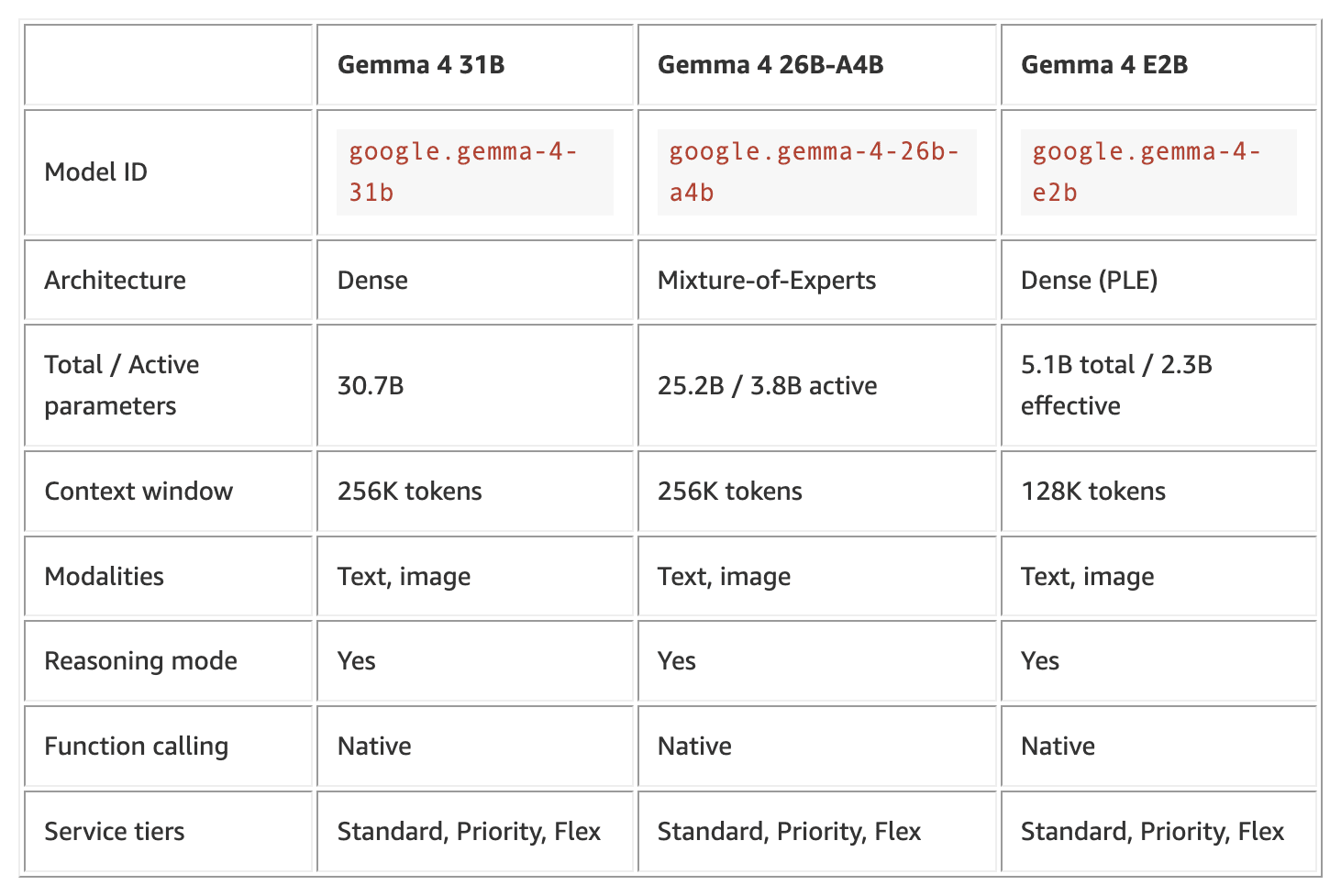
It comes in 3 variants (different architecture) which solves for different use cases:
| Model | Model ID |
|---|---|
| Gemma 4 31B | google.gemma-4-31b |
| Gemma 4 26B-A4B | google.gemma-4-26b-a4b |
| Gemma 4 E2B | google.gemma-4-e2b |
Feel free to copy and paste this into your Markdown file.
How to use it?
It is available through bedrock-mantle endpoint which exposes the inference via OpenAI-compatible APIs
All you need to do is just replace the base url with bedrock-mantle url (make sure to configure proper region) and include the AWS Bedrock key when making the request.
You can refer to recent post on how to use OpenAI models on AWS Bedrock
Chat Completion
curl --location 'https://bedrock-mantle.us-east-2.api.aws/v1/chat/completions' \
--header 'Authorization: Bearer $AWS_BEDROCK_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "google.gemma-4-31b",
"messages": [
{
"role": "system",
"content": "You are concise and helpful."
},
{
"role": "user",
"content": "What is the capital of Japan?"
}
]
}'
And we’ll be getting response like this
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Tokyo.",
"refusal": null,
"role": "assistant"
}
}
],
"created": 1781629710,
"id": "chatcmpl-d2f5fb58-62b1-41c7-844f-e227ec657b55",
"model": "google.gemma-3-4b-it",
"object": "chat.completion",
"service_tier": "default",
"usage": {
"completion_tokens": 3,
"prompt_tokens": 23,
"total_tokens": 26
}
}
Responses API
curl --location 'https://bedrock-mantle.us-east-2.api.aws/openai/v1/responses' \
--header 'Authorization: Bearer $AWS_BEDROCK_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "google.gemma-4-31b",
"input": [
{
"role": "system",
"content": "You are concise and helpful."
},
{
"role": "user",
"content": "What is the capital of Japan?"
}
]
}'
And we’ll be getting response like this
{
"background": false,
"billing": {
"payer": "developer"
},
"completed_at": 1781630375,
"created_at": 1781630375,
"error": null,
"frequency_penalty": 0.0,
"id": "resp_ry7cyzezapihrdlug3kngpqmh2a6u453rtacpe7upspurt7tj7ta",
"incomplete_details": null,
"instructions": null,
"max_output_tokens": null,
"max_tool_calls": null,
"metadata": {},
"model": "google.gemma-4-31b",
"object": "response",
"output": [
{
"content": [
{
"annotations": [],
"logprobs": [],
"text": "The capital of Japan is Tokyo.",
"type": "output_text"
}
],
"id": "msg_da37bc558e1e55bc810b2310a0801c25",
"phase": "final_answer",
"role": "assistant",
"status": "completed",
"type": "message"
}
],
"parallel_tool_calls": true,
"presence_penalty": 0.0,
"previous_response_id": null,
"prompt_cache_key": null,
"prompt_cache_retention": "in_memory",
"reasoning": {
"effort": "medium",
"summary": null,
"context": "current_turn"
},
"safety_identifier": null,
"service_tier": "default",
"status": "completed",
"store": true,
"temperature": 1.0,
"text": {
"format": {
"type": "text"
},
"verbosity": "medium"
},
"tool_choice": "auto",
"tools": [],
"top_logprobs": 0,
"top_p": 0.98,
"truncation": "disabled",
"usage": {
"input_tokens": 32,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 8,
"output_tokens_details": {
"reasoning_tokens": 0
},
"total_tokens": 40
},
"user": null,
"moderation": null
}