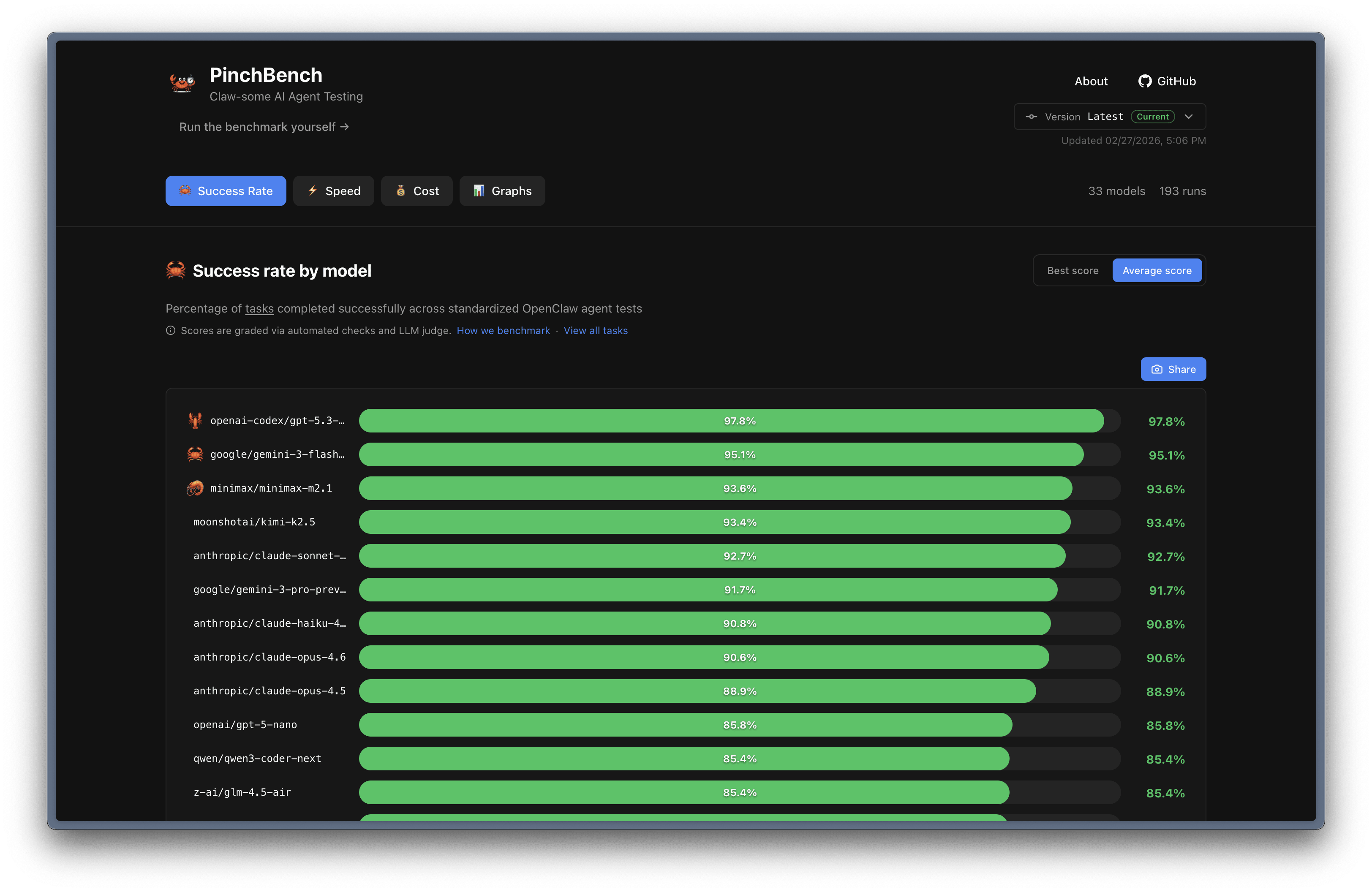
LLM Model Benchmark for OpenClaw

If you’re wondering which model perform well for which task for your OpenClaw bot, you might need to checkout
Why PinchBench?
Most LLM benchmarks test isolated capabilities. PinchBench tests what actually matters for coding agents:
Tool usage — Can the model call the right tools with the right parameters?
Multi‑step reasoning — Can it chain together actions to complete complex tasks?
Real‑world messiness — Can it handle ambiguous instructions and incomplete information?
Practical outcomes — Did it actually create the file, send the email, or schedule the meeting?
I’m surprised to see gemini-3-flash-preview as one of the top model in that list 😁